

[R] 10. 피어슨 상관계수(Pearson's Corrleation)
반응형
예시로 쓰일 데이터 예제
set.seed(2021)
# 임의로 데이터를 생성한다. (100명의 유저가 특정 곡을 스트리밍한 이력)
temp <- tibble(
user_id = c(10000:10149),
user_age = sample(x = round(runif(n = 50, min = 18, max = 50), 0), size = 150, replace = TRUE),
user_gender = sample(x = c("남성", "여성"), size = 150, prob = c(0.5, 0.5), replace = TRUE),
song_id = sample(x = letters[1:15], size = 150, replace = TRUE),
streaming_count = rpois(n = 150, lambda = 20),
download_count = rpois(n = 150, lambda = 5)
) %>%
mutate(
song_class_flag = case_when(
song_id %in% c("d", "e", "f") ~ "인기곡",
TRUE ~ "비인기곡"
)
)
temp## # A tibble: 150 x 7
## user_id user_age user_gender song_id streaming_count download_count
## <int> <dbl> <chr> <chr> <int> <int>
## 1 10000 44 여성 e 20 6
## 2 10001 47 남성 f 21 6
## 3 10002 49 남성 k 14 3
## 4 10003 44 남성 j 8 4
## 5 10004 26 여성 f 20 5
## 6 10005 44 여성 j 17 2
## 7 10006 20 여성 j 24 3
## 8 10007 27 남성 l 24 1
## 9 10008 34 여성 f 20 5
## 10 10009 26 남성 d 27 6
## # … with 140 more rows, and 1 more variable: song_class_flag <chr>피어슨 상관계수(Pearson’s Correlation)
- 피어슨 상관계수는 여러 다양한 상관계수들 중 하나이지만, 가장 널리 사용하기 때문에 흔히 그냥 상관계수라고만 불리기도 합니다.
- 피어슨 상관계수는 두 개의 변수가 모두 연속형 변수일 경우,
두 변수의 선형관계(linear relationship)를 정량화하고자 할 때 사용합니다. - 만일 두 변수의 스케일이 상이하다면 적절한 표준화(normalize) 작업이 사전에 필요하기도 합니다.
- 아래 예시 데이터로 설명을 하겠습니다.
# 스트리밍 횟수(x축)와 다운로드 횟수(y축) 간 산점도
temp %>%
ggplot(aes(x = streaming_count, y = download_count)) +
geom_point(size = 1.2)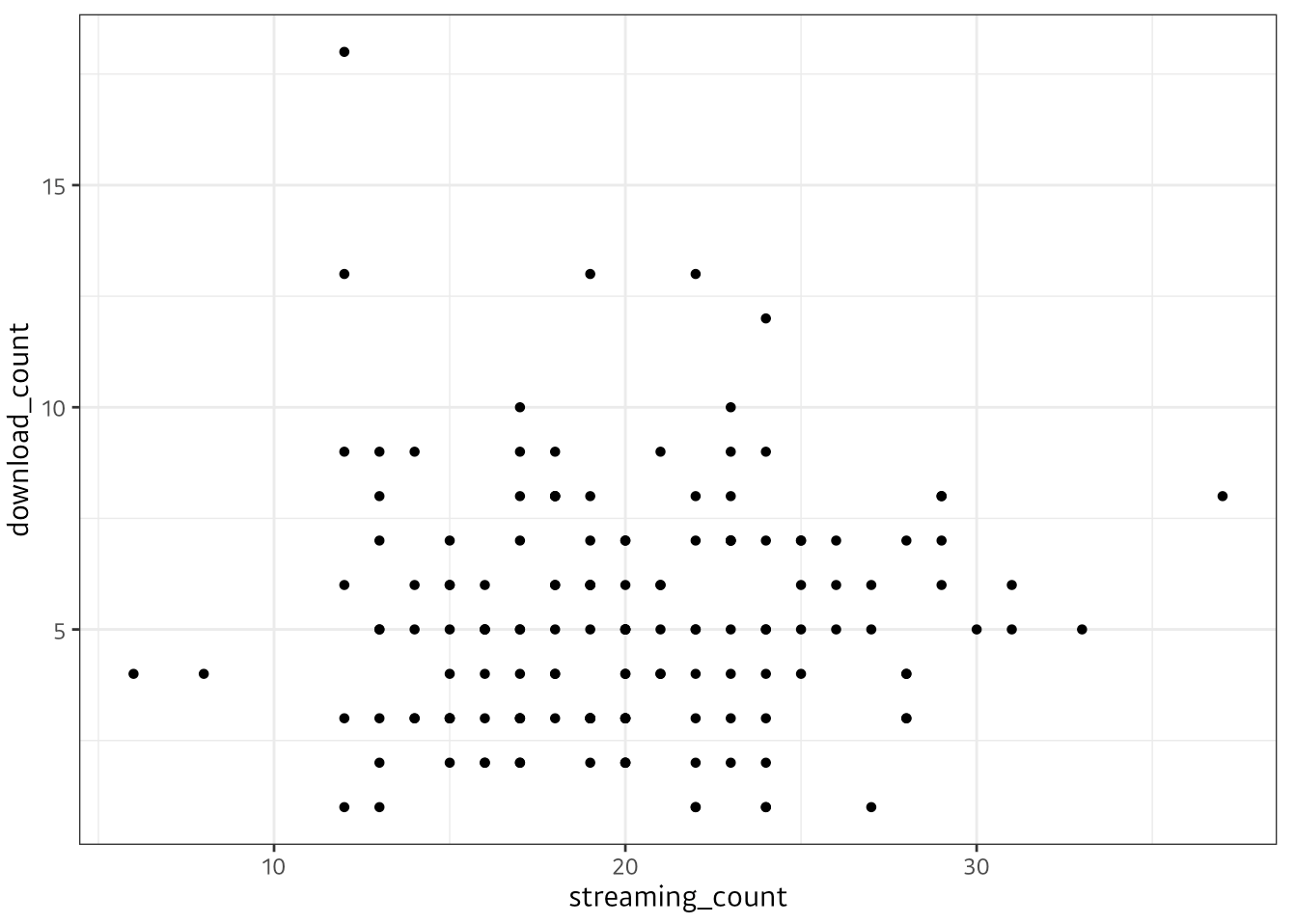
- 위의 산점도만 보면 어느 정도 선형관계가 있어보이긴 합니다만,
실제 상관성을 확인하기 위해 아래 코드와 같이cor.test()함수를 사용하여 상관분석을 해보겠습니다.
temp %>%
cor.test(~ streaming_count + download_count, data = .)##
## Pearson's product-moment correlation
##
## data: streaming_count and download_count
## t = 0.33632, df = 148, p-value = 0.7371
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## -0.1332169 0.1870676
## sample estimates:
## cor
## 0.02763458- 그 결과 p-value 값은 흔히 우리가 정의할 수 있는 유의수준인 0.05보다 높으므로 유의수준 0.05 하에 해당 귀무가설을 기각할 수 없습니다.
- (귀무가설: 두 변수의 상관계수는 0이다)
- 따라서 두 변수간에 상관계수는 0이라고 말할 수 있습니다.
- 실제 상관계수의 95% 신뢰구간을 보시면 그 구간안에 0이 포함될 수 있음을 확인할 수 있습니다.
- 만일 성별로 나누어서 보고 싶다면?
split()함수와map()함수를 적절하게 사용하시면 됩니다.- 여기서
map()함수를 사용하게 되면 함수 내부의 데이터를.이 아니라.x와 같은 형태로 지정받게 됩니다.
- 여기서
temp %>%
split(.$user_gender) %>%
map(~ cor.test(~ streaming_count + download_count, data = .x))## $남성
##
## Pearson's product-moment correlation
##
## data: streaming_count and download_count
## t = -0.48684, df = 76, p-value = 0.6278
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## -0.2748771 0.1688691
## sample estimates:
## cor
## -0.05575697
##
##
## $여성
##
## Pearson's product-moment correlation
##
## data: streaming_count and download_count
## t = 0.77705, df = 70, p-value = 0.4397
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## -0.1422390 0.3173467
## sample estimates:
## cor
## 0.09247693
- 결과 통계량 값만 깔끔하게 tibble 형태로 받고 싶다면,
broom라이브러리의tidy()함수를 적용하면 됩니다.
library(broom)
# 성별 나눔 없이 분석
temp %>%
cor.test(~ streaming_count + download_count, data = .) %>%
tidy()## # A tibble: 1 x 8
## estimate statistic p.value parameter conf.low conf.high method alternative
## <dbl> <dbl> <dbl> <int> <dbl> <dbl> <chr> <chr>
## 1 0.0276 0.336 0.737 148 -0.133 0.187 Pearson's… two.sided# 성별 나누어서 분석 + map()
temp %>%
split(.$user_gender) %>%
map(~ cor.test(~ streaming_count + download_count, data = .x)) %>%
map(~ tidy(.))## $남성
## # A tibble: 1 x 8
## estimate statistic p.value parameter conf.low conf.high method alternative
## <dbl> <dbl> <dbl> <int> <dbl> <dbl> <chr> <chr>
## 1 -0.0558 -0.487 0.628 76 -0.275 0.169 Pearson's… two.sided
##
## $여성
## # A tibble: 1 x 8
## estimate statistic p.value parameter conf.low conf.high method alternative
## <dbl> <dbl> <dbl> <int> <dbl> <dbl> <chr> <chr>
## 1 0.0925 0.777 0.440 70 -0.142 0.317 Pearson's… two.sided# 성별 나누어서 분석 + map_dfr()
temp %>%
split(.$user_gender) %>%
map(~ cor.test(~ streaming_count + download_count, data = .x)) %>%
map_dfr(~ tidy(.))## # A tibble: 2 x 8
## estimate statistic p.value parameter conf.low conf.high method alternative
## <dbl> <dbl> <dbl> <int> <dbl> <dbl> <chr> <chr>
## 1 -0.0558 -0.487 0.628 76 -0.275 0.169 Pearson's… two.sided
## 2 0.0925 0.777 0.440 70 -0.142 0.317 Pearson's… two.sided반응형
'tidyverse' 카테고리의 다른 글
| [R] 12. 카이제곱 검정(chi-squared test) (0) | 2021.07.13 |
|---|---|
| [R] 11. t-Test (0) | 2021.07.13 |
| [R] 9. 기술통계분석 (0) | 2021.07.05 |
| [R] 8. 데이터 합치기 (join) (0) | 2021.07.05 |
| [R] 7. 데이터 형태 변환 (0) | 2021.07.05 |
TAGS.