

[R] 4. Relationships between words: n-grams and correlations
반응형
4. Relationships between words: n-grams and correlations
4. 1. Tokenizing by n-gram
- 지금까지
unnset_tokens()함수를 사용하여 단어, 또는 문장으로 토큰화를 진행했었는데,
이러한 토큰 단위는 감정 또는 빈도 관련 분석에 유용합니다. - 그러나 해당 함수를 사용하여 n-grams라고 하는 연속적인 단어 시퀀스로도 토큰화를 할 수 있습니다.
- 즉, 어느 단어 다음에 특정 단어가 얼마나 자주 나오는 지 확인함으로써 이들 사이의 관계를 확인해볼 수도 있습니다.
- 방식은 간단합니다.
unnest_tokens()함수에token = "ngrams"와n = 2(연속되는 단어 수) arguments를 주면 됩니다.
library(janeaustenr)austen_bigrams <- austen_books() %>%
unnest_tokens(input = text, output = "bigram", token = "ngrams", n = 2)
austen_bigrams## # A tibble: 675,025 x 2
## book bigram
## <fct> <chr>
## 1 Sense & Sensibility sense and
## 2 Sense & Sensibility and sensibility
## 3 Sense & Sensibility <NA>
## 4 Sense & Sensibility by jane
## 5 Sense & Sensibility jane austen
## 6 Sense & Sensibility <NA>
## 7 Sense & Sensibility <NA>
## 8 Sense & Sensibility <NA>
## 9 Sense & Sensibility <NA>
## 10 Sense & Sensibility <NA>
## # … with 675,015 more rows4. 1. 1. Counting and filtering n-grams
- 이도 마찬가지로
count()함수를 사용하여 빈도를 체크해볼 수 있습니다.
austen_bigrams %>%
count(bigram, sort = TRUE)## # A tibble: 193,210 x 2
## bigram n
## <chr> <int>
## 1 <NA> 12242
## 2 of the 2853
## 3 to be 2670
## 4 in the 2221
## 5 it was 1691
## 6 i am 1485
## 7 she had 1405
## 8 of her 1363
## 9 to the 1315
## 10 she was 1309
## # … with 193,200 more rowsseparate()함수는 구분자를 기준으로 컬럼을 여러 개로 분할하는 데 쓰일 수 있는 함수 입니다.- 이 함수를 가지고 위 결과를 두 개의 컬럼으로 분리할 수 있습니다.
astuen_bigrams결과가 두 개의 단어를 띄어쓰기 공백으로 분리하였기에 구분자는띄어쓰기 한 칸이 됩니다.
bigrams_separated <- austen_bigrams %>%
separate(
col = bigram,
into = c("word1", "word2"),
sep = " "
)
bigrams_separated## # A tibble: 675,025 x 3
## book word1 word2
## <fct> <chr> <chr>
## 1 Sense & Sensibility sense and
## 2 Sense & Sensibility and sensibility
## 3 Sense & Sensibility <NA> <NA>
## 4 Sense & Sensibility by jane
## 5 Sense & Sensibility jane austen
## 6 Sense & Sensibility <NA> <NA>
## 7 Sense & Sensibility <NA> <NA>
## 8 Sense & Sensibility <NA> <NA>
## 9 Sense & Sensibility <NA> <NA>
## 10 Sense & Sensibility <NA> <NA>
## # … with 675,015 more rowsstop_words를 활용하여 불용어를 제거한 후 빈도를 확인해보곘습니다.
data("stop_words")
bigrams_filtered <- bigrams_separated %>%
filter(!word1 %in% stop_words$word) %>%
filter(!word2 %in% stop_words$word)
bigram_counts <- bigrams_filtered %>%
count(word1, word2, sort = TRUE)
bigram_counts## # A tibble: 28,975 x 3
## word1 word2 n
## <chr> <chr> <int>
## 1 <NA> <NA> 12242
## 2 sir thomas 266
## 3 miss crawford 196
## 4 captain wentworth 143
## 5 miss woodhouse 143
## 6 frank churchill 114
## 7 lady russell 110
## 8 sir walter 108
## 9 lady bertram 101
## 10 miss fairfax 98
## # … with 28,965 more rows- Jane Austen의 책에서는 이름과 성이 가장 빈도가 높은 한 쌍임을 알 수 있습니다.
- 또 다른 분석에서는 재결합된 단어로 작업할 수 있습니다.
unite()함수는separate()함수와 반대로 열을 하나로 다시 결합할 수 있습니다.- 따라서
separate(),filter(),count(),unite()함수를 사용하여 가장 일반적인 두 단어 쌍을 찾을 수 있습니다.
bigrams_united <- bigrams_filtered %>%
unite(
col = "bigram",
word1, word2,
sep = " "
)
bigrams_united## # A tibble: 51,155 x 2
## book bigram
## <fct> <chr>
## 1 Sense & Sensibility NA NA
## 2 Sense & Sensibility jane austen
## 3 Sense & Sensibility NA NA
## 4 Sense & Sensibility NA NA
## 5 Sense & Sensibility NA NA
## 6 Sense & Sensibility NA NA
## 7 Sense & Sensibility NA NA
## 8 Sense & Sensibility NA NA
## 9 Sense & Sensibility chapter 1
## 10 Sense & Sensibility NA NA
## # … with 51,145 more rows4. 1. 2. Analyzing bigrams
- 우리는 각 책에 언급된 “street”라는 단어에 관심이 있다고 가정합시다.
- “street” 단어 이전에 어떤 단어들이 많이 나왔는 지 EDA 관점에서 접근하고 싶다면? 아래와 같이 입력해볼 수 있습니다.
bigrams_filtered %>%
filter(word2 == "street") %>%
count(book, word1, srot = TRUE)## # A tibble: 33 x 4
## book word1 srot n
## <fct> <chr> <lgl> <int>
## 1 Sense & Sensibility berkeley TRUE 15
## 2 Sense & Sensibility bond TRUE 4
## 3 Sense & Sensibility conduit TRUE 4
## 4 Sense & Sensibility harley TRUE 16
## 5 Sense & Sensibility james TRUE 1
## 6 Sense & Sensibility park TRUE 1
## 7 Sense & Sensibility sackville TRUE 1
## 8 Pride & Prejudice edward TRUE 1
## 9 Pride & Prejudice gracechurch TRUE 8
## 10 Pride & Prejudice grosvenor TRUE 2
## # … with 23 more rows
- 또한 ngram 역시 문장 단위 안에서 토큰으로 취급한 것이기에 TF-IDF 계산도 가능합니다.
bigram_tf_idf <- bigrams_united %>%
count(book, bigram) %>%
bind_tf_idf(
term = bigram,
document = book,
n = n
) %>%
arrange(desc(tf_idf))
bigram_tf_idf %>%
group_by(book) %>%
slice_max(tf_idf, n = 10) %>%
ungroup() %>%
ggplot(aes(x = reorder(bigram, tf_idf), y = tf_idf, fill = book)) +
geom_col(show.legend = FALSE) +
facet_wrap(~ book, ncol = 2, scales = "free") +
coord_flip() +
labs(x = "bi-gram", y = NULL)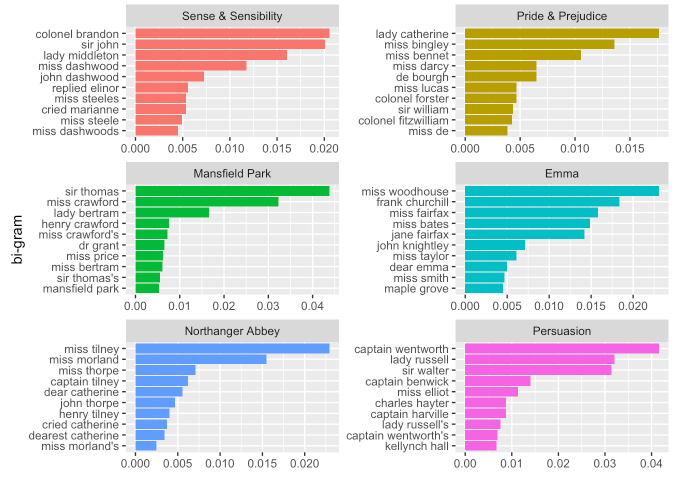
- 개별 단어보다 ngram의 TF-IDF는 단일 단어를 계산할 때 보이지 않는 구조를 포착하고 토큰을 더 이해하기 쉽게 만드는 데 도움을 줍니다.
4. 1. 3. Using bigrams to provide context in sentiment analysis
- 챕터 2에서는 사전을 활용하여 단순히 긍정적이거나 부정적인 단어의 빈도를 계산하였습니다.
- 이제는 ngram을 구성하였으므로 단어 앞에 “not”과 같은 단어가 오는 빈도도 알 수 있습니다.
bigrams_separated %>%
filter(word1 == "not") %>%
count(word1, word2, sort = TRUE)## # A tibble: 1,178 x 3
## word1 word2 n
## <chr> <chr> <int>
## 1 not be 580
## 2 not to 335
## 3 not have 307
## 4 not know 237
## 5 not a 184
## 6 not think 162
## 7 not been 151
## 8 not the 135
## 9 not at 126
## 10 not in 110
## # … with 1,168 more rows- 이를 가지고 AFINN 사전을 사용하여 각 단어에 대한 감정을 수치로 표현하고자 합니다.
not_words <- bigrams_separated %>%
filter(word1 == "not") %>%
inner_join(get_sentiments("afinn"), by = c(word2 = "word")) %>%
count(word2, value, sort = TRUE)
not_words## # A tibble: 229 x 3
## word2 value n
## <chr> <dbl> <int>
## 1 like 2 95
## 2 help 2 77
## 3 want 1 41
## 4 wish 1 39
## 5 allow 1 30
## 6 care 2 21
## 7 sorry -1 20
## 8 leave -1 17
## 9 pretend -1 17
## 10 worth 2 17
## # … with 219 more rows- 위 결과 중 하나를 보면 “not” 뒤에 오는 가장 일반적인 감정 관련 단어는 “like”이며 점수는 2입니다.
- 이처럼 어떤 단어가 negative에 많이 기여했는지도 확인해볼 수 있습니다.
- 단어 별 value 값에 빈도를 곱한 결과로 확인해볼 수 있습니다.
not_words %>%
mutate(contribution = n*value) %>%
arrange(desc(abs(contribution))) %>%
head(20) %>%
ggplot(aes(x = reorder(word2, contribution), y = contribution, fill = contribution > 0)) +
geom_col(show.legend = FALSE) +
coord_flip() +
labs(y = "Sentiment value * number of occurrences", x = "Words preceded by \"not\"")
4 1. 4. Visualizing a network of bigrams with ggraph
- 한 단어에 상위 몇 개만 표시하는 것을 넘어서 단어 간의 모든 관계를 동시에 시각화하는 데 관심이 있을 수 있습니다.
- 이는 네트워크 그래프를 활용하여 정렬해볼 수 있습니다. (연결된 노드의 조합을 보이는 그래프 포맷)
- 이 때 활용한 라이브러리는
igraph라이브러리이며 tidy data에서 igraph 객체를 생성하는 함수인graph_from_data_frame()함수를 사용할 것 입니다. - 또한 시각화에는
ggraph라이브러리를 사용합니다.igraph라이브러리에도 플로팅 함수가 있지만ggplot2문법이 익숙한 시각화 라이브러리인ggraph라이브러리를 사용합니다.
library(igraph)##
## 다음의 패키지를 부착합니다: 'igraph'## The following objects are masked from 'package:dplyr':
##
## as_data_frame, groups, union## The following objects are masked from 'package:purrr':
##
## compose, simplify## The following object is masked from 'package:tidyr':
##
## crossing## The following object is masked from 'package:tibble':
##
## as_data_frame## The following objects are masked from 'package:stats':
##
## decompose, spectrum## The following object is masked from 'package:base':
##
## unionlibrary(ggraph)bigram_counts## # A tibble: 28,975 x 3
## word1 word2 n
## <chr> <chr> <int>
## 1 <NA> <NA> 12242
## 2 sir thomas 266
## 3 miss crawford 196
## 4 captain wentworth 143
## 5 miss woodhouse 143
## 6 frank churchill 114
## 7 lady russell 110
## 8 sir walter 108
## 9 lady bertram 101
## 10 miss fairfax 98
## # … with 28,965 more rowsbigram_graph <- bigram_counts %>%
filter(n > 20) %>% # 빈도가 20회가 넘는 두 단어의 조합 식별
graph_from_data_frame()## Warning in graph_from_data_frame(.): In `d' `NA' elements were replaced with
## string "NA"bigram_graph## IGRAPH 68c3987 DN-- 86 71 --
## + attr: name (v/c), n (e/n)
## + edges from 68c3987 (vertex names):
## [1] NA ->NA sir ->thomas miss ->crawford
## [4] captain ->wentworth miss ->woodhouse frank ->churchill
## [7] lady ->russell sir ->walter lady ->bertram
## [10] miss ->fairfax colonel ->brandon sir ->john
## [13] miss ->bates jane ->fairfax lady ->catherine
## [16] lady ->middleton miss ->tilney miss ->bingley
## [19] thousand->pounds miss ->dashwood dear ->miss
## [22] miss ->bennet miss ->morland captain ->benwick
## + ... omitted several edges- 위 객체를 가지고
ggraph()함수를 적용하여igraph객체를ggraph객체로 변환할 수 있습니다. - 이후
ggplot2에서 레이어를 추가하는 것처럼 레이어를 추가하여 진행합니다. - 기본적으로 노드(node)와 가장자리(edge), 그리고 텍스트(text) 세 가지 레이어를 추가해야 합니다.
set.seed(2021)
ggraph(bigram_graph, layout = "fr") +
geom_edge_link() +
geom_node_point() +
geom_node_text(aes(label = name), vjust = 1, hjust = 1)
- 위 그래프에서 보면 “miss”, “lady”, “sir” 등의 단어를 중심으로 공통의 노드를 형성하고 종종 뒤에 이름이 붙는 것을 확인할 수 있습니다.
- 더 나은 모양의 그래프를 만들기 위해 아래와 같이 몇 가지 작업으로 마무리합니다.
ggraph(bigram_graph, layout = "fr") +
geom_edge_link(
aes(edge_alpha = n),
arrow = grid::arrow(type = "closed", length = unit(.15, "inches")),
end_cap = circle(.07, "inches"),
show.legend = FALSE
) +
geom_node_point(color = "lightblue", size = 5) +
geom_node_text(aes(label = name), vjust = 1, hjust = 1) +
theme_void()
4. 2. Counting and correlating pairs of words with the widyr package
- 위에서 살펴보았듯 ngram으로 토큰화하는 작업은 인접한 단어 쌍을 탐색하는 유용한 방법입니다.
- 그러나 우리는 특정 문서나 특정 챕터에서 나란히 발생하지 않는 경우에도 함께 발생할 가능성이 있는 단어에 관심을 가질 수 있습니다.
- tidy data는 변수를 비교하거나 그룹화하는 데 있어서 유용한 구조이지만 행간의 비교는 다소 어려울 수 있습니다.
- 예를 들어 두 단어가 동일한 문서에서 나타나는 횟수를 계산하거나 두 단어가 얼마나 상관관계가 있는 지 확인하기 위해서는 데이터를 wide format으로 변환해야 합니다. (행렬꼴)
widyr라이브러리는 이러한 부분에 있어서 도움을 줄 수 있습니다.
4. 2. 1. Counting and correlating among sections
- 아래 “Pride & Prejudice” 책의 내용을 가지고 단어들을 토큰화 시켜보겠습니다.
- 섹션을 나누는 기준은 10줄 단위로 하겠습니다.
austen_section_words <- austen_books() %>%
filter(book == "Pride & Prejudice") %>%
mutate(section = row_number() %/% 10) %>%
filter(section > 0) %>%
unnest_tokens(
input = text,
output = "word",
token = "words"
) %>%
filter(!word %in% stop_words$word)
austen_section_words## # A tibble: 37,240 x 3
## book section word
## <fct> <dbl> <chr>
## 1 Pride & Prejudice 1 truth
## 2 Pride & Prejudice 1 universally
## 3 Pride & Prejudice 1 acknowledged
## 4 Pride & Prejudice 1 single
## 5 Pride & Prejudice 1 possession
## 6 Pride & Prejudice 1 fortune
## 7 Pride & Prejudice 1 wife
## 8 Pride & Prejudice 1 feelings
## 9 Pride & Prejudice 1 views
## 10 Pride & Prejudice 1 entering
## # … with 37,230 more rowswidyr의 유용한 함수 중 하나는pairwise_count()함수입니다.pairwise_는word변수의 각 단어 쌍에 대해 하나의 행을 구성하는 의미입니다.itemarguments에 단어가 들어가게 되고,featurearguments에 각 섹션이 들어가게 됩니다.
library(widyr)word_pairs <- austen_section_words %>%
pairwise_count(
item = word,
feature = section,
sort = TRUE
)## Warning: `distinct_()` was deprecated in dplyr 0.7.0.
## Please use `distinct()` instead.
## See vignette('programming') for more help## Warning: `tbl_df()` was deprecated in dplyr 1.0.0.
## Please use `tibble::as_tibble()` instead.word_pairs## # A tibble: 796,008 x 3
## item1 item2 n
## <chr> <chr> <dbl>
## 1 darcy elizabeth 144
## 2 elizabeth darcy 144
## 3 miss elizabeth 110
## 4 elizabeth miss 110
## 5 elizabeth jane 106
## 6 jane elizabeth 106
## 7 miss darcy 92
## 8 darcy miss 92
## 9 elizabeth bingley 91
## 10 bingley elizabeth 91
## # … with 795,998 more rows- 그 결과 각 섹션에서 단어의 쌍에 대해 하나의 행으로 구성된 데이터가 출력됩니다.
- 이를 통해 섹션 단위 기준으로 특정 단어와 함께 자주 노출되는 단어를 쉽게 찾을 수 있습니다.
# darcy는 elizabeth와 같은 주인공 인물이라고 합니다.
word_pairs %>%
filter(item1 == "darcy")## # A tibble: 2,930 x 3
## item1 item2 n
## <chr> <chr> <dbl>
## 1 darcy elizabeth 144
## 2 darcy miss 92
## 3 darcy bingley 86
## 4 darcy jane 46
## 5 darcy bennet 45
## 6 darcy sister 45
## 7 darcy time 41
## 8 darcy lady 38
## 9 darcy friend 37
## 10 darcy wickham 37
## # … with 2,920 more rows4. 2. 2. Pairwise correlation
- 아래 표를 가지고 파이 계수를 아래와 같이 정의할 수 있습니다.
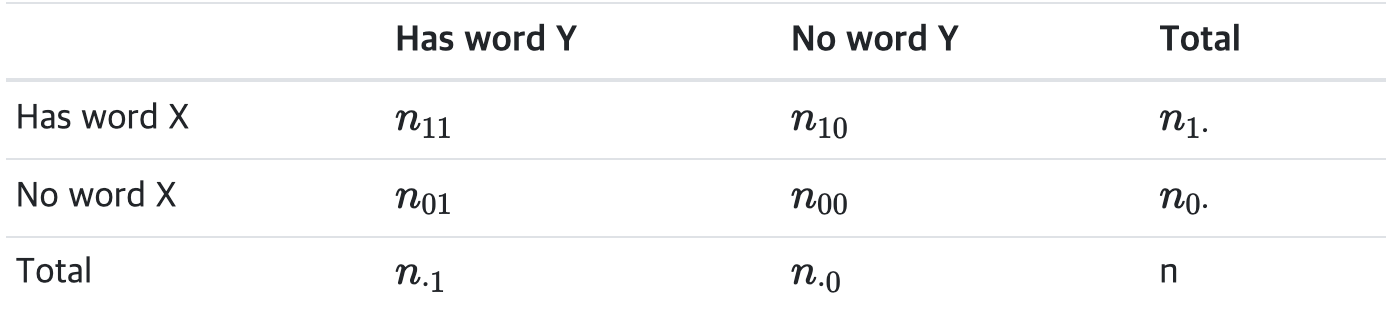

- 이는 binary data에서의 피어슨 상관계수와 동일한 포맷입니다.
- 두 단어의 상관계수를 구하려면
pairwise_col()함수를 사용할 수 있습니다.
word_corr <- austen_section_words %>%
group_by(word) %>%
filter(n() > 20) %>%
ungroup() %>%
pairwise_cor(
item = word,
feature = section,
sort = TRUE
)
word_corr## # A tibble: 140,250 x 3
## item1 item2 correlation
## <chr> <chr> <dbl>
## 1 bourgh de 0.951
## 2 de bourgh 0.951
## 3 pounds thousand 0.701
## 4 thousand pounds 0.701
## 5 william sir 0.664
## 6 sir william 0.664
## 7 catherine lady 0.663
## 8 lady catherine 0.663
## 9 forster colonel 0.622
## 10 colonel forster 0.622
## # … with 140,240 more rows- 이를 통해 특정 관심있는 단어를 필터링하여 가장 상관성이 높은 다른 단어를 찾을 수 있습니다.
word_corr %>%
filter(item1 %in% c("elizabeth", "pounds", "married", "pride")) %>%
group_by(item1) %>%
slice_max(correlation, n = 6) %>%
ungroup() %>%
ggplot(aes(x = reorder(item2, correlation), y = correlation)) +
geom_bar(stat = "identity", colour = "black", fill = "grey85") +
facet_wrap(~ item1, scales = "free") +
coord_flip()
- 마찬가지로
ggraph라이브러리를 활용하여 상관계수에 기반한 네트워크 그래프를 출력할 수 있습니다.
word_corr %>%
filter(correlation > .15) %>% # 상관계수가 0.15를 넘는 단어 쌍에 대해서만 필터링
graph_from_data_frame() %>%
ggraph(layout = "fr") +
geom_edge_link(aes(edge_alpha = correlation), show.legend = FALSE) +
geom_node_point(color = "lightblue", size = 5) +
geom_node_text(aes(label = name), repel = TRUE) + # repel = TRUE arguments는 라벨링의 가독성에 도움을 줌
theme_void()
반응형
'tidytext' 카테고리의 다른 글
| [R] 6. Topic modeling (0) | 2021.07.20 |
|---|---|
| [R] 5. Converting to and from non-tidy formats (0) | 2021.07.19 |
| [R] 3. Analyzing word and document frequency: TF-IDF (0) | 2021.07.18 |
| [R] 한글 형태소 분석 (0) | 2021.07.17 |
| [R] unnest_tokens() (0) | 2021.07.17 |
TAGS.